Hadoop-04 YARN
YARN
旧的MapReduce的架构:
- JobTracker:负责资源管理,跟踪资源消耗和可用性,作业生命周期管理(调度作业任务,跟踪进度,为任务提供容错)
- TaskTracker:加载或关闭任务,定时报告任务状态。
此架构会有以下问题:
- JobTracker是MapReduce的集中处理点,存在单点故障。
- JobTracker完成了太多的任务,造成了过多的资源消耗,当MapReduce Job非常多的时候,会造成很大的内存开销。这也是业界普遍总结出老版本Hadoop的MapReduce只能支持4000节点的主机上限。
- 在TaskTracker端,以map/reduce task的数目作为资源的表示过于简单,没有考虑到cpu/内存的占用情况,如果两个大内存消耗的task被调度的一起,很容易出现OOM。
- 在TaskTracker端,把资源强制划分为map task slot 和 reduce task slot,如果当系统中只有map task或者只有reduce task的时候,会造成资源浪费,也就是集群资源的利用问题。
总结就是单点问题和资源利用率问题。
yarn的架构:


YARN就是把JobTracker的职责拆分,将资源管理和任务调度监控拆分成独立的进程,一个全局的资源管理和一个每个作业的管理(ApplicationMaster)ResourceManager和NodeManager提供了计算资源的分配和管理,而ApplicationMaster则完成应用程序的运行。
- ResourceManager : RM – 全局资源管理和任务调度
- 整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度。
- 处理客户端的请求:提交一个作业,杀死一个作业
- 监控NM,一旦NM挂了,那么改NM上运行的任务需要告诉AM来如何进行处理
- NodeManager: NM – 单个节点的资源管理和监控
- 整个集群中有多个,负责自己本身节点资源管理和使用
- 定时向RM汇报本节点的资源使用情况
- 接受并处理来自RM的各种命令:启动Container
- 处理来自AM的命令
- 每个节点的资源管理
- ApplicationMaster: AM – 单个作业的资源管理和任务监控
- 每个应用程序对应一个:MR、Spark,负责应用程序的管理
- 为应用程序向RM申请资源(core、memory),分配给内部task
- 需要与NM通信: 启动/停止task,task是运行在container里面,AM也是运行在Container里面的
- Container – 资源申请的单位和任务运行的容器
- 封装了CPU、Memory等资源的一个容器
- 是一个任务运行环境的抽象
- Client
- 提交作业
- 查询作业的运行进度
- 杀死作业
架构对比

YARN架构下形成了一个通用的资源管理平台和一个通用的应用计算平台。避免了旧架构的单点问题和资源利用率的问题,同时也让在其上运行的应用不局限于MapReduce形式。
YARN的基本流程

- Job submission
- 从ResourceManager中获取一个Application ID检查作业输出配置,计算输入分片拷贝作业资源(job jar、配置文件、分片信息)到HDFS,以便后面任务的执行。
- Job initialization
- ResourceManager将作业递交给Scheduler(有很多算法,一般根据优先级)Scheduler为作业分配一个Container,ResourceManager就加载一个application master process 并交给NodeManager。
- 管理ApplicationMaster主要是创建一系列的监控进程来跟踪作业的调度,同时获取输入分片,为每一个分片创建一个Map task和相应的reduce task Application Master ,还决定如何运行作业,如果作业很小(可配置),则直接在同一个JVM下运行。
- Task assignment
- ApplicationMaster 向Resource Manager 申请资源(一个个的Container,指定任务分配资源要求)一般是根据data locality来分配资源。
- Task execution
- ApplicationMaster根据ResourceManager的分配情况,在对应的NodeManager中启动Container从HDFS中读取任务所需资源(job jar ,配置文件等)然后执行该任务。
- Progress and status update
- 定时将任务的进度和状态报告给ApplicationMaster Client 定时向ApplicationMaster获取整个任务的进度和状态。
- Job completion
- Client 定时检查整个作业是否完成,作业完成后,会清空临时文件,目录。
YARN - ResourceManager
负责全局的资源管理和任务调度,把整个集群当成计算资源池,只关注分配,不管应用,且不负责容错。
资源管理
- 以前资源是每个节点分成一个个的Map slot和Reduce slot,现在是一个个Container,每个Container可以根据需要运行ApplicationMaster、map、Reduce或任意的程序。
- 以前的资源分配是静态的,目前是动态的,资源利用率更高。
- Container是资源申请的单位,一个资源申请格式:
<resource-name, priority, resource-requirement, number-of-containers>, resource-name:主机名、机架名或*(代表任意机器), resource-requirement:目前只支持CPU和内存 - 用户提交作业到ResourceManger ,然后在某个NodeManager上分配一个Container来运行ApplicationMaster,ApplicationMaster再根据自身程序需要向ResourceManager申请资源。
- YARN有一套Container的生命周期管理机制,而ApplicationMaster和其Container之间的管理是应用程序自己定义的。
任务调度
- 只关注资源的使用情况,根据需求合理分配资源。
- Schedule可以根据申请的需要,在特定的机器上申请特定的资源(ApplicationMaster负责申请资源时的数据本地化的考虑,ResourceManager将尽量满足其申请需求,在指定的机器上分配Container,从而减少数据移动)。
内部结构
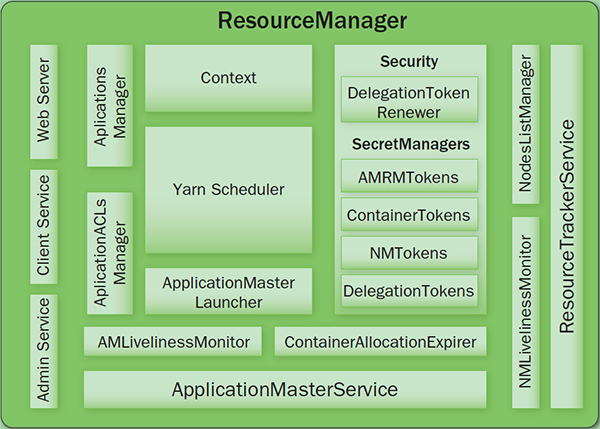
- Client Service: 应用提交、终止、输出信息(应用、队列、集群等的状态信息)。
- Adaminstration Service: 队列、节点、Client权限管理。
- ApplicationMasterService: 注册、终止ApplicationMaster, 获取ApplicationMaster的资源申请或取消的请求,并将其异步地传给Scheduler, 单线程处理。
- ApplicationMaster Liveliness Monitor: 接收ApplicationMaster的心跳消息,如果某个ApplicationMaster在一定时间内没有发送心跳,则被任务失效,其资源将会被回收,然后ResourceManager会重新分配一个ApplicationMaster运行该应用(默认尝试2次)。
- Resource Tracker Service: 注册节点, 接收各注册节点的心跳消息。
- NodeManagers Liveliness Monitor: 监控每个节点的心跳消息,如果长时间没有收到心跳消息,则认为该节点无效, 同时所有在该节点上的Container都标记成无效,也不会调度任务到该节点运行。
- ApplicationManager: 管理应用程序,记录和管理已完成的应用。
- ApplicationMaster Launcher: 一个应用提交后,负责与NodeManager交互,分配Container并加载ApplicationMaster,也负责终止或销毁。
- YarnScheduler: 资源调度分配, 有FIFO(with Priority),Fair,Capacity方式。
- ContainerAllocationExpirer: 管理已分配但没有启用的Container,超过一定时间则将其回收。
YARN - NodeManager
Node节点下的Container管理
- 启动时向ResourceManager注册并定时发送心跳信息,等待ResourceManager的指令。
- 监控Container的运行,维护Container的生命周期,监控Container的资源使用情况。
- 启动或停止Container,管理任务运行时的依赖包(根据ApplicationMaster的需要,启动Container之前将需要的程序及其依赖包、配置文件等拷贝到本地)。
-
NodeStatusUpdater: 启动向ResourceManager注册,报告该节点的可用资源情况,通信的端口和后续状态的维护。
-
ContainerManager: 接收RPC请求(启动、停止),资源本地化(下载应用需要的资源到本地,根据需要共享这些资源)。
PUBLIC: /filecache PRIVATE: /usercache//filecache APPLICATION: /usercache//appcache//(在程序完成后会被删除) -
ContainersLauncher: 加载或终止Container。
-
ContainerMonitor: 监控Container的运行和资源使用情况。
-
ContainerExecutor: 和底层操作系统交互,加载要运行的程序。
YARN - ApplicationMaster
单个作业的资源管理和任务监控
具体功能描述:
- 计算应用的资源需求,资源可以是静态或动态计算的,静态的一般是Client申请时就指定了,动态则需要ApplicationMaster根据应用的运行状态来决定。
- 根据数据来申请对应位置的资源(Data Locality)。
- 向ResourceManger申请资源,与NodeManger交互进行程序的运行和监控,监控申请的资源的使用情况,监控作业调度。
- 跟踪任务状态和调度,定时向ResourceManger发送心跳信息,报告资源的使用情况和应用的进度信息。
- 负责本作业内的任务的容错。
ApplicationMaster可以是用任何语言编写的程序,它和ResourceManger和NodeManager之间通过protocolBuf交互,以前是一个全局的JobTracker负责的,现在每个左右都一个,可伸缩性更强,至少不会因为作业太多,造成JobTracker瓶颈。同时将作业的逻辑放到一个独立的ApplicationMaster中,使得灵活性更高,每个作业都可以由自己的处理方式,不用绑定到MapReduce的处理模式上。
如何计算资源需求:
一般的MapReduce是根据block数量来定Map和Reduce的计算数量,然后一般的Map或Reduce就占用一个Container。
如何发现数据的本地化:
数据本地化是通过HDFS的block分片信息获取的
YARN - Container
- 基本的资源单位(cpu、内存等)。
- Container可以加载任何程序,而且不限于java。
- 一个Node可以包含多个Container,也可以是一个大的Container。
- ApplicationMaster可以根据需要,动态申请和释放Container。
YARN - Failover
失败类型
- 程序问题。
- 进程崩溃。
- 硬件问题。
失败处理
任务失败
- 运行时异常或者JVM退出都会报告给ApplicationMaster。
- 通过心跳来检查挂住的任务(timeout),会检查多次(可配置)才判断该任务是否失效。
- 一个作业的任务失败率超过配置,则认为该作业失败。
- 失败的任务或作业都会有ApplicationMaster重新运行。
ApplicationMaster失败
- ApplicationMaster定时发送心跳信号到ResourceManager,通常一旦ApplicationMaster失败,则认为失败,但也可以通过配置多次后才失败
- 一旦ApplicationMaster失败,ResourceManager会启动一个新的ApplicationMaster
- 新的ApplicationMaster负责恢复之前错误的ApplicationMaster的状(yarn.app.mapreduce.am.job.recovery.enable=true),这一步是通过将应用运行状态保存到共享的存储上来实现的,ResourceManager不会负责任务状态的保存和恢复
- Client也会定时向ApplicationMaster查询进度和状态,一旦发现其失败,则向ResouceManager询问新的ApplicationMaster
NodeManager失败
- NodeManager定时发送心跳到ResourceManager,如果超过一段时间没有收到心跳消息,ResourceManager就会将其移除
- 任何运行在该NodeManager上的任务和ApplicationMaster都会在其他NodeManager上进行恢复
- 如果某个NodeManager失败的次数太多,ApplicationMaster会将其加入黑名单(ResourceManager没有),任务调度时不在其上运行任务
ResourceManager失败
- 通过checkpoint机制,定时将其状态保存到磁盘,然后失败的时候,重新运行
- 通过zookeeper同步状态和实现透明的HA
可以看出,一般的错误处理都是由当前模块的父模块进行监控(心跳)和恢复。而最顶端的模块则通过定时保存、同步状态和zookeeper来ֹ实现HA
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!