Hadoop-05 MapReduce
MapReduce
旧的MapReduce的架构:
一种分布式的计算方式指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(规约)函数,用来保证所有映射对中的每一个共享相同的键组。
如图:
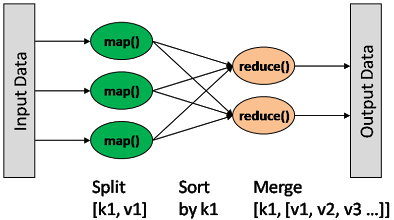
map: (K1, V1) → list(K2, V2) combine: (K2, list(V2)) → list(K2, V2) reduce: (K2, list(V2)) → list(K3, V3)
Map输出格式和Reduce输入格式一定是相同的
基本流程
MapReduce主要是先读取文件数据,然后进行Map处理,接着Reduce处理,最后把处理结果写到文件中。
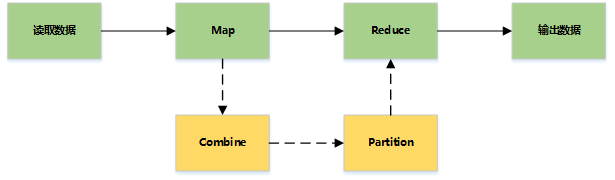
详细流程
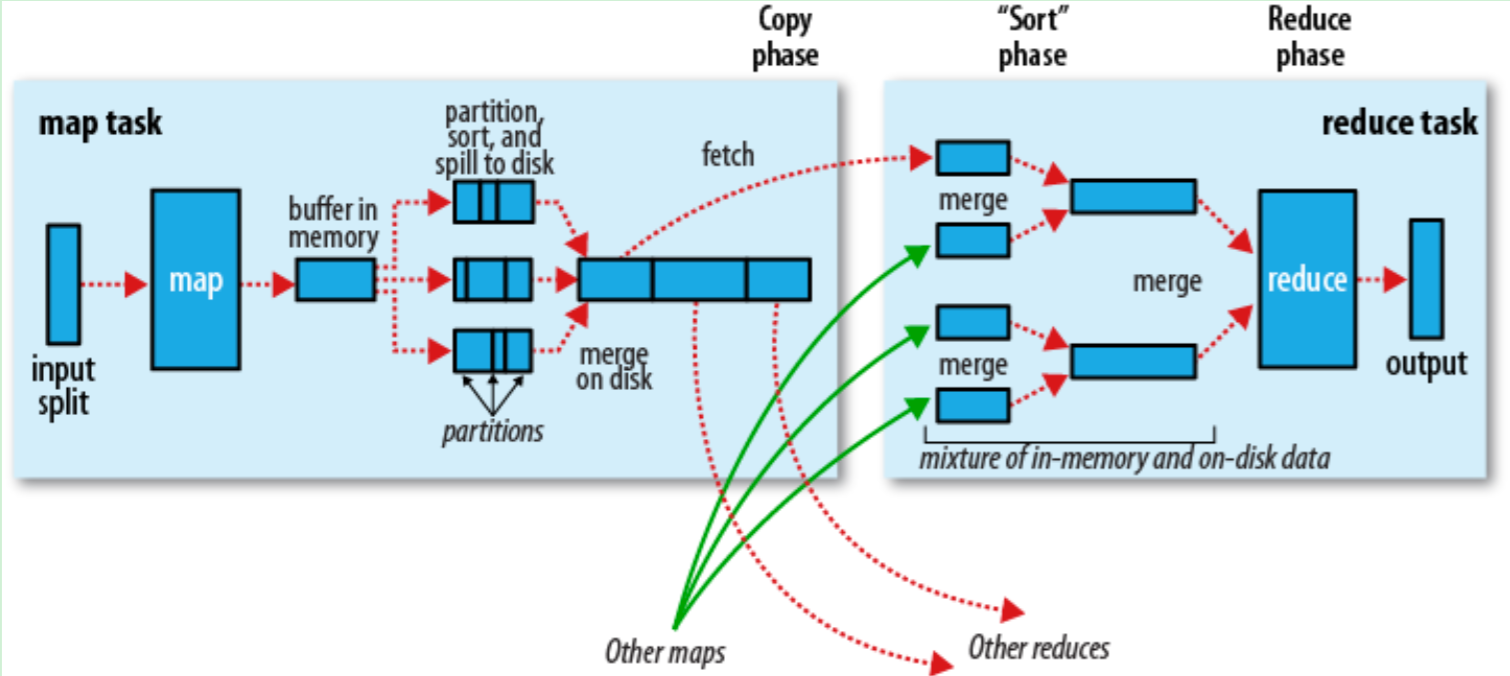
多节点下的流程
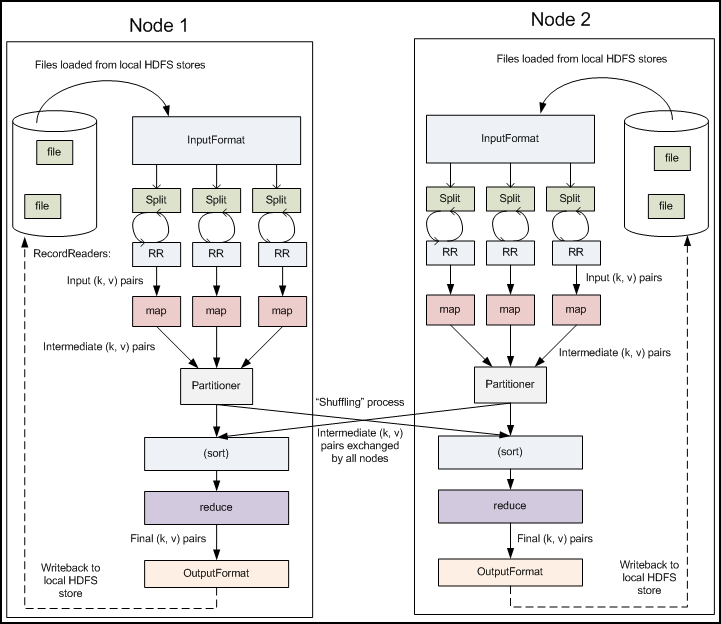
主要过程

Map Side
Record reader
记录阅读器会翻译由输入格式生成的记录,记录阅读器用于将数据解析给记录,并不分析记录自身。记录读取器的目的是将数据解析成记录,但不分析记录本身。它将数据以键值树的形式传输给mapper,通常是位置信息,值是构成记录的数据存储块,自定义记录不在本文讨论范围之内。
Map
在映射器中用户提供的代称为中间对。对于键值的具体定义是慎重的,因为定义对于分布式任务的完成具有重要意义。键决定了数据分类的依据,而值决定了处理器中的分析信息。
Shuffle and Sort
reduce任务以随机和排序的步骤开始,此步骤写入输出文件并下载到本地计算机,这些数据采用键进行排序以把等价密钥组合到一起。
Reduce
reduce采用分组数据作为输入,该功能传递键和此键相关值的迭代器。可以采用多种方式来汇总、过滤或者合并数据。当reduce功能完成,就会发送0个或多个键值对。
输出格式
输出格式会转换最终的键值对并写人文件。默认情况下键和值以tab分割,各记录以换行符分割。因此可以自定义更多输出格式,最终数据会写入HDFS。
MapReude - 读取数据
通过InputFormat决定读取的数据类型,然后拆分成一个个InputSplit,每个InputSplit对应一个Map处理,RecordReader读取InputSplit的内容给Map。
InputFormat
决定读取数据的格式,可以是文件或者数据库等。
功能:
- 验证作业输入的正确性,如格式等。
- 将输入文件切割成逻辑分片(InputSplit),一个InputSplit将会被分配给一个独立的Map任务。
- 提供RecordReader实现,读取InputSplit中“K-V”对供Mapper使用。
方法:
List getSplits():获取由输入文件计算出输入分片(InputSplit),解决数据或文件分割成片问题。
RecordReader createRecordReader(): 创建RecordReader,从InputSplit中读取数据,解决读取分片中的数据问题。
类结构
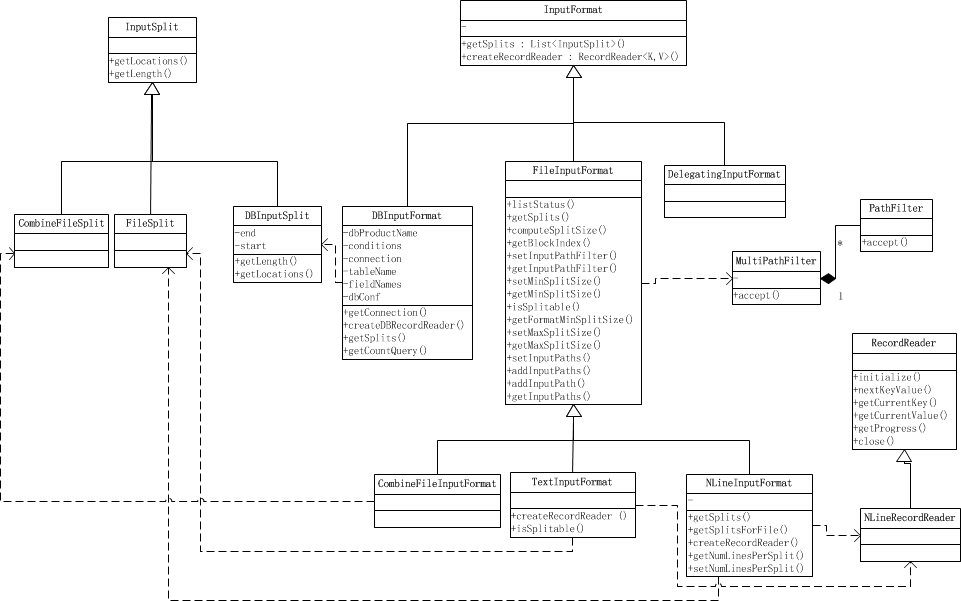
- TextInputFormat: 输入文件中的每一行就是一个记录,Key是这一行的byte offset,而value是这一行的内容
- KeyValueTextInputFormat: 输入文件中每一行就是一个记录,第一个分隔符字符切分每行。在分隔符字符之前的内容为Key,在之后的为Value。分隔符变量通过key.value.separator.in.input.line变量设置,默认为(\t)字符。
- NLineInputFormat: 与TextInputFormat一样,但每个数据块必须保证有且只有N行,mapred.line.input.format.linespermap属性,默认为1
- SequenceFileInputFormat: 一个用来读取字符流数据的InputFormat,<key,value>为用户自定义的。字符流数据是Hadoop自定义的压缩的二进制数据格式。它用来优化从一个MapReduce任务的输出到另一个MapReduce任务的输入之间的数据传输过程。</key,value>
InputSplit
代表一个个逻辑分片,并没有真正存储数据,只是提供了一个如何将数据分片的方法
Split内有Location信息,利于数据局部化
一个InputSplit给一个单独的Map处理
1 | |
RecordReader
将InputSplit拆分成一个个<key,value>对给Map处理,也是实际的文件读取分隔对象</key,value>
问题
大量小文件如何处理
CombineFileInputFormat可以将若干个Split打包成一个,目的是避免过多的Map任务(因为Split的数目决定了Map的数目,大量的Mapper Task创建销毁开销将是巨大的)
怎么计算split的
通常一个split就是一个block(FileInputFormat仅仅拆分比block大的文件),这样做的好处是使得Map可以在存储有当前数据的节点上运行本地的任务,而不需要通过网络进行跨节点的任务调度
通过mapred.min.split.size, mapred.max.split.size, block.size来控制拆分的大小
如果mapred.min.split.size大于block size,则会将两个block合成到一个split,这样有部分block数据需要通过网络读取
如果mapred.max.split.size小于block size,则会将一个block拆成多个split,增加了Map任务数(Map对split进行计算并且上报结果,关闭当前计算打开新的split均需要耗费资源)
先获取文件在HDFS上的路径和Block信息,然后根据splitSize对文件进行切分( splitSize = computeSplitSize(blockSize, minSize, maxSize) ),默认splitSize 就等于blockSize的默认值(64m)
1 | |
分片间的数据如何处理
split是根据文件大小分割的,而一般处理是根据分隔符进行分割的,这样势必存在一条记录横跨两个split

解决办法是只要不是第一个split,都会远程读取一条记录。不是第一个split的都忽略到第一条记录
1 | |
MapReduce - Mapper
主要是读取InputSplit的每一个Key,Value对并进行处理
1 | |
MapReduce - Shuffle
对Map的结果进行排序并传输到Reduce进行处理Map的结果并不是直接存放在硬盘,而是利用缓存做一些与排序处理Map会调用Combiner,压缩,按key进行分区,排序等。尽量减少结果的大小每个Map完成后都会通知Task,然后Reduce就可以进行处理。
Map端
- 当Map程序开始产生结果的时候,并不是直接写到文件的,而是利用缓存做一些排序方面的预处理操作
- 每个Map任务都有一个循环内存缓冲区(默认100MB),当缓存的内容达到80%时,后台线程开始将内容写到文件,此时Map任务可以继续输出结果,但如果缓冲区满了,Map任务则需要等待
- 写文件使用round-robin方式。在写入文件之前,先将数据按照Reduce进行分区。对于每一个分区,都会在内存中根据key进行排序,如果配置了Combiner,则排序后执行Combiner(Combine之后可以减少写入文件和传输的数据)
- 每次结果达到缓冲区的阀值时,都会创建一个文件,在Map结束时,可能会产生大量的文件。在Map完成前,会将这些文件进行合并和排序。如果文件的数量超过3个,则合并后会再次运行Combiner(1、2个文件就没有必要了)
- 如果配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据
- 一旦Map完成,则通知任务管理器,此时Reduce就可以开始复制结果数据
Reduce端
- Map的结果文件都存放到运行Map任务的机器的本地硬盘中
- 如果Map的结果很少,则直接放到内存,否则写入文件中
- 同时后台线程将这些文件进行合并和排序到一个更大的文件中(如果文件是压缩的,则需要先解压)
- 当所有的Map结果都被复制和合并后,就会调用Reduce方法
Reduce结果会写入到HDFS中
调优
- 一般的原则是给shuffle分配尽可能多的内存,但前提是要保证Map、Reduce任务有足够的内存
- 对于Map,主要就是避免把文件写入磁盘,例如使用Combiner,增大io.sort.mb的值
- 对于Reduce,主要是把Map的结果尽可能地保存到内存中,同样也是要避免把中间结果写入磁盘。默认情况下,所有的内存都是分配给Reduce方法的,如果Reduce方法不怎么消耗内存,可以mapred.inmem.merge.threshold设成0,mapred.job.reduce.input.buffer.percent设成1.0
- 在任务监控中可通过Spilled records counter来监控写入磁盘的数,但这个值是包括map和reduce的
- 对于IO方面,可以Map的结果可以使用压缩,同时增大buffer size(io.file.buffer.size,默认4kb)
配置
| 属性 | 默认值 | 描述 |
|---|---|---|
| io.sort.mb | 100 | 映射输出分类时所使用缓冲区的大小. |
| io.sort.record.percent | 0.05 | 剩余空间用于映射输出自身记录.在1.X发布后去除此属性.随机代码用于使用映射所有内存并记录信息. |
| io.sort.spill.percent | 0.80 | 针对映射输出内存缓冲和记录索引的阈值使用比例. |
| io.sort.factor | 10 | 文件分类时合并流的最大数量。此属性也用于reduce。通常把数字设为100. |
| min.num.spills.for.combine | 3 | 组合运行所需最小溢出文件数目. |
| mapred.compress.map.output | false | 压缩映射输出. |
| mapred.map.output.compression.codec | DefaultCodec | 映射输出所需的压缩解编码器. |
| mapred.reduce.parallel.copies | 5 | 用于向reducer传送映射输出的线程数目. |
| mapred.reduce.copy.backoff | 300 | 时间的最大数量,以秒为单位,这段时间内若reducer失败则会反复尝试传输 |
| io.sort.factor | 10 | 组合运行所需最大溢出文件数目. |
| mapred.job.shuffle.input.buffer.percent | 0.70 | 随机复制阶段映射输出缓冲器的堆栈大小比例 |
| mapred.job.shuffle.merge.percent | 0.66 | 用于启动合并输出进程和磁盘传输的映射输出缓冲器的阀值使用比例 |
| mapred.inmem.merge.threshold | 1000 | 用于启动合并输出和磁盘传输进程的映射输出的阀值数目。小于等于0意味着没有门槛,而溢出行为由 mapred.job.shuffle.merge.percent单独管理. |
| mapred.job.reduce.input.buffer.percent | 0.0 | 用于减少内存映射输出的堆栈大小比例,内存中映射大小不得超出此值。若reducer需要较少内存则可以提高该值. |
MapReduce - 编程
处理
- select:直接分析输入数据,取出需要的字段数据即可
- where: 也是对输入数据处理的过程中进行处理,判断是否需要该数据
- aggregation:min, max, sum
- group by: 通过Reducer实现
- sort
- join: map join, reduce join
优点:海量数据里离线处理,易开发,易运行
缺点:实时流式计算
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
核心概念:
split:交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元。
HDFS:blocksize 是hdfs中最小的存储单元, 128M
默认情况下:他们两是一一对应的,可以手工设置(不建议)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!